AD INTELLIGENCE
Statistically real winners, not lucky ones.
Adscalr tells you which creative is a winner you can trust, and which test to run next. It scores every creative on the six metrics that move money, steadies small samples so a twelve-impression fluke can't crown itself, and trusts only the patterns that survive false-discovery correction. A Thompson-sampling bandit then points your next test where it buys the most learning. Kill, scale and next test: all three defensible.

How it works
Six metrics, weighted by funnel stage
Hook rate, CTR, CPI, ROAS, share rate and revenue-per-install blend into one composite, with weights tuned per project and per funnel stage, cold to hot. For static ads with no hook rate, that weight is cleanly redistributed to CTR and CPI, so there's no hole in the score.
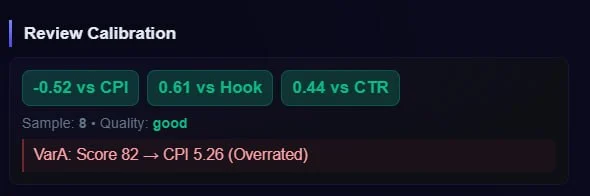
Lucky outliers can't pose as winners
Before anything is ranked, every metric is pulled toward the portfolio mean with Bayesian shrinkage, and the pull is format-specific: a static earns trust at 500 pseudo-impressions, a UGC clip needs 3,000, because UGC performs far more volatilely. A twelve-impression fluke never becomes your next winner.
Real patterns, not coincidence
Correlations between hook, color, format and angle are filtered with Benjamini–Hochberg false-discovery correction at q=0.10, behind two hard gates: a group of at least eight creatives and an effect size of 10% or more. Test twenty dimensions and you'd otherwise find "significant" noise by definition. The correction closes that hole.
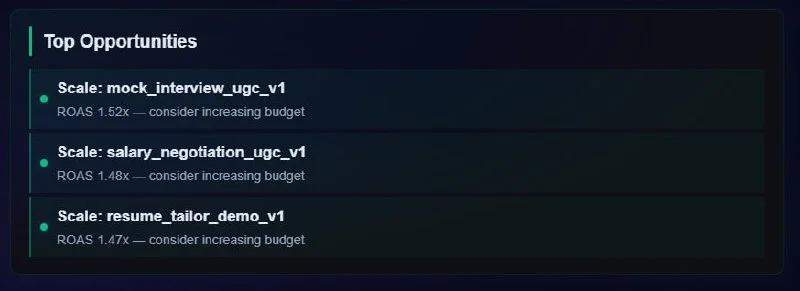
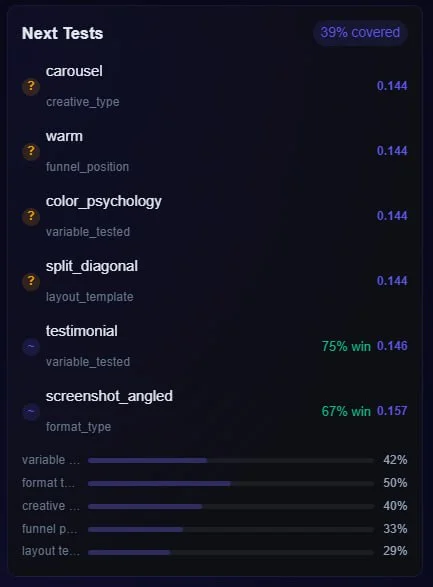
Your next test, chosen by math
A multi-armed bandit decides where your next euro of testing learns the most: for each test dimension it draws from a Beta posterior and ranks by expected information gain. Explore versus exploit, balanced automatically.
Learning-mode spend can't dictate patterns
Every ad gets a phase by spend (learning under €200, stabilizing to just under €1,000, proven at €1,000 and up), and learning-phase creatives count just 0.25× in pattern mining. An ad still settling in Meta's learning mode can't write a rule before it's proven.
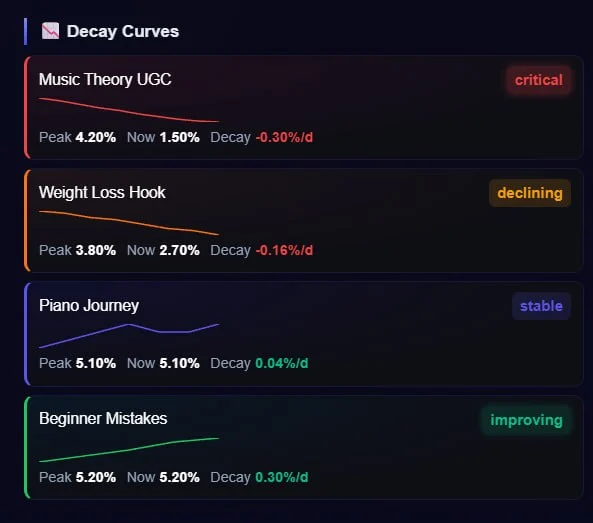
Decay-weighted, fatigue-aware
Recent data counts full; from week thirteen it counts about 5%. Three fatigue signals (novelty decay, audience exhaustion and mixed) read a multi-day CTR trend, with a predictive early warning for how many days until the threshold breaks, and a market-wide check that separates "your creative is tired" from "the whole market dipped."
THE DIFFERENTIATOR
Not just what won, what to test next.
Most tools tell you which creative won. Adscalr tells you whether the win is real, and which test to run next. A Thompson-sampling bandit treats every test dimension as an arm, samples from its Beta posterior and ranks by expected information gain, so the next euro you spend testing buys the most learning.
Explore vs. exploit, balanced
Proven dimensions and unexplored ones compete on the same posterior, so you neither over-test a known winner nor ignore a promising unknown.
Expected information gain, ranked
Each candidate test is scored by how much it would actually teach you. The recommendation is the test that moves your knowledge the most.
Reproducible by the week
Recommendations are seeded per project and calendar week, so they're stable across the week, not a different answer on every reload.
What you get
- Composite scoring from 6 metrics, funnel-weighted
- Bayesian shrinkage with format-specific priors (static 500 … UGC 3,000)
- FDR-corrected pattern mining (q=0.10) with n≥8 and a ≥10% effect gate
- Thompson-sampling test recommendations, refreshed weekly
- Geo / PPP normalization of CPI & ROAS across a 50-country table, before scoring
- 3 fatigue signals + predictive early warning + market-wide correction
- Attention heatmaps & 5-point scanpath for statics (DeepGazeIIE, neural)
By the numbers
Want this running on your account?
Get in touch →